For many applications, the data one needs to cope with for a
major scientific innovation or discovery is immense,
distributed, and unstructured. Thanks to the advancements on
computer hardware and storage technologies, we currently have
good arsenals to manage it. However, not every
hardware-algorithm combination is effective and efficient enough
to provide an insight that can make an impact on science,
technology, and hence, on the public. And even with the best
combination at hand, the performance we settle for today will
not be sufficient in the future since the data growth is
exponential; around 90% of the data we have is generated in the
last two years.
Efficiency is not only a concern when the data is large: for
time-critical applications, one needs to utilize the
architecture at hand as efficient as possible. Today’s
architectures are driven by power limitations; instead of using
a single, very fast, power-hungry core, the CPUs we currently
use have relatively slower cores. To get further computing power
within a reasonable power envelope, accelerators have been
developed by packing much simpler cores into a single die.
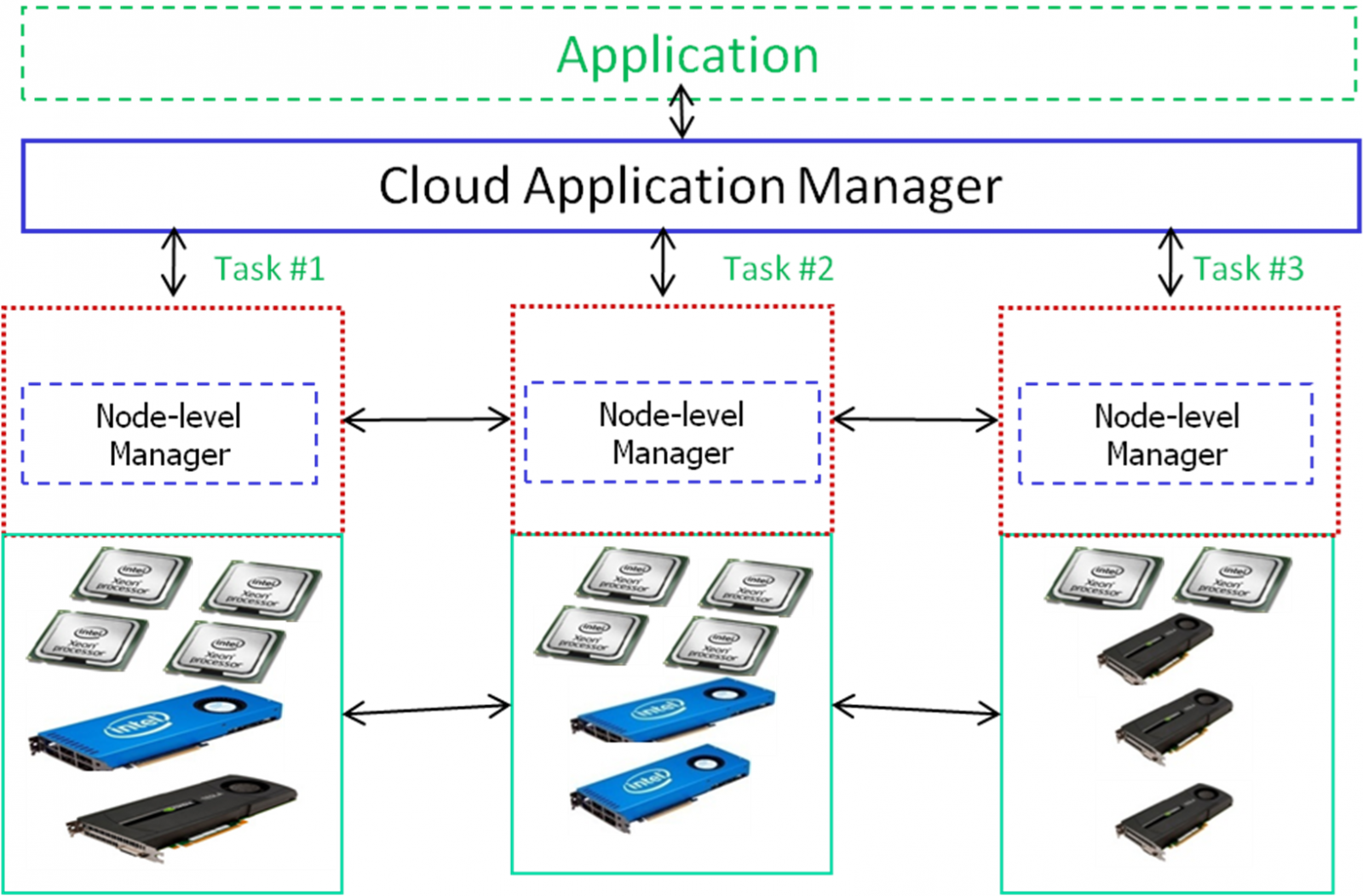
Today, the world's most powerful supercomputers contain
heterogeneous nodes which are equipped with cutting-edge
multicore CPUs, faster SSDs, as well as accelerators, such as
GPUs with thousands of cores or Intel's Xeon Phi. Due to this
heterogeneity, applying different parallelization techniques at
different levels of hardware/software is a necessity to achieve
the peak performance and fully utilize such architectures. At
Sabancı University, we conduct HPC research on social network
analysis, combinatorial algorithms for scientific computing and
runtime middleware systems for emerging multi-core
architectures.

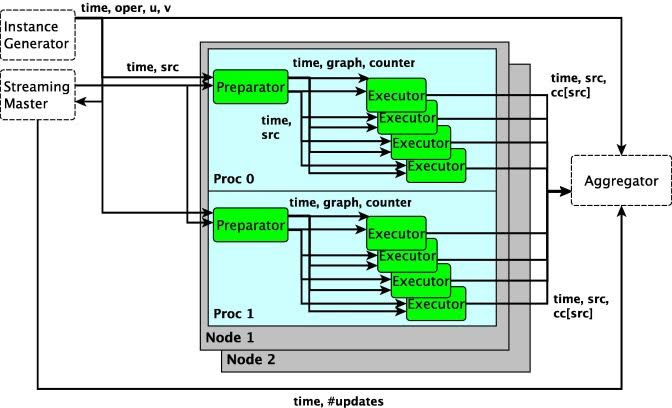 Computing centralities of the people in a social network in
parallel with a high-performance computing cluster having
multiple nodes. There are three levels of parallelization: node,
NUMA domain, and core.
Computing centralities of the people in a social network in
parallel with a high-performance computing cluster having
multiple nodes. There are three levels of parallelization: node,
NUMA domain, and core.